|
|
@@ -143,9 +143,14 @@ Index, hints and integrity
|
|
|
|
|
|
The **repository index** is stored in ``index.<TRANSACTION_ID>`` and is used to
|
|
|
determine an object's location in the repository. It is a HashIndex_,
|
|
|
-a hash table using open addressing. It maps object keys_ to two
|
|
|
-unsigned 32-bit integers; the first integer gives the segment number,
|
|
|
-the second indicates the offset of the object's entry within the segment.
|
|
|
+a hash table using open addressing.
|
|
|
+
|
|
|
+It maps object keys_ to:
|
|
|
+
|
|
|
+* segment number (unit32)
|
|
|
+* offset of the object's entry within the segment (uint32)
|
|
|
+* size of the payload, not including the entry header (uint32)
|
|
|
+* flags (uint32)
|
|
|
|
|
|
The **hints file** is a msgpacked file named ``hints.<TRANSACTION_ID>``.
|
|
|
It contains:
|
|
|
@@ -153,6 +158,8 @@ It contains:
|
|
|
* version
|
|
|
* list of segments
|
|
|
* compact
|
|
|
+* shadow_index
|
|
|
+* storage_quota_use
|
|
|
|
|
|
The **integrity file** is a msgpacked file named ``integrity.<TRANSACTION_ID>``.
|
|
|
It contains checksums of the index and hints files and is described in the
|
|
|
@@ -176,17 +183,9 @@ Since writing a ``DELETE`` tag does not actually delete any data and
|
|
|
thus does not free disk space any log-based data store will need a
|
|
|
compaction strategy (somewhat analogous to a garbage collector).
|
|
|
|
|
|
-Borg uses a simple forward compacting algorithm,
|
|
|
-which avoids modifying existing segments.
|
|
|
+Borg uses a simple forward compacting algorithm, which avoids modifying existing segments.
|
|
|
Compaction runs when a commit is issued with ``compact=True`` parameter, e.g.
|
|
|
by the ``borg compact`` command (unless the :ref:`append_only_mode` is active).
|
|
|
-One client transaction can manifest as multiple physical transactions,
|
|
|
-since compaction is transacted, too, and Borg does not distinguish between the two::
|
|
|
-
|
|
|
- Perspective| Time -->
|
|
|
- -----------+--------------
|
|
|
- Client | Begin transaction - Modify Data - Commit | <client waits for repository> (done)
|
|
|
- Repository | Begin transaction - Modify Data - Commit | Compact segments - Commit | (done)
|
|
|
|
|
|
The compaction algorithm requires two inputs in addition to the segments themselves:
|
|
|
|
|
|
@@ -198,9 +197,6 @@ The compaction algorithm requires two inputs in addition to the segments themsel
|
|
|
to be stored as well. Therefore, Borg stores a mapping ``(segment
|
|
|
id,) -> (number of sparse bytes,)``.
|
|
|
|
|
|
- The 1.0.x series used a simpler non-conditional algorithm,
|
|
|
- which only required the list of sparse segments. Thus,
|
|
|
- it only stored a list, not the mapping described above.
|
|
|
(ii) Each segment's reference count, which indicates how many live objects are in a segment.
|
|
|
This is not strictly required to perform the algorithm. Rather, it is used to validate
|
|
|
that a segment is unused before deleting it. If the algorithm is incorrect, or the reference
|
|
|
@@ -209,14 +205,7 @@ The compaction algorithm requires two inputs in addition to the segments themsel
|
|
|
These two pieces of information are stored in the hints file (`hints.N`)
|
|
|
next to the index (`index.N`).
|
|
|
|
|
|
-When loading a hints file, Borg checks the version contained in the file.
|
|
|
-The 1.0.x series writes version 1 of the format (with the segments list instead
|
|
|
-of the mapping, mentioned above). Since Borg 1.0.4, version 2 is read as well.
|
|
|
-The 1.1.x series writes version 2 of the format and reads either version.
|
|
|
-When reading a version 1 hints file, Borg 1.1.x will
|
|
|
-read all sparse segments to determine their sparsity.
|
|
|
-
|
|
|
-This process may take some time if a repository has been kept in append-only mode
|
|
|
+Compaction may take some time if a repository has been kept in append-only mode
|
|
|
or ``borg compact`` has not been used for a longer time, which both has caused
|
|
|
the number of sparse segments to grow.
|
|
|
|
|
|
@@ -578,7 +567,7 @@ dictionary created by the ``Item`` class that contains:
|
|
|
* source (for symlinks)
|
|
|
* hlid (for hardlinks)
|
|
|
* rdev (for device files)
|
|
|
-* mtime, atime, ctime in nanoseconds
|
|
|
+* mtime, atime, ctime, birthtime in nanoseconds
|
|
|
* xattrs
|
|
|
* acl (various OS-dependent fields)
|
|
|
* flags
|
|
|
@@ -689,14 +678,14 @@ In memory, the files cache is a key -> value mapping (a Python *dict*) and conta
|
|
|
|
|
|
- file inode number
|
|
|
- file size
|
|
|
- - file mtime_ns
|
|
|
+ - file ctime_ns (or mtime_ns)
|
|
|
- age (0 [newest], 1, 2, 3, ..., BORG_FILES_CACHE_TTL - 1)
|
|
|
- list of chunk ids representing the file's contents
|
|
|
|
|
|
To determine whether a file has not changed, cached values are looked up via
|
|
|
the key in the mapping and compared to the current file attribute values.
|
|
|
|
|
|
-If the file's size, mtime_ns and inode number is still the same, it is
|
|
|
+If the file's size, timestamp and inode number is still the same, it is
|
|
|
considered to not have changed. In that case, we check that all file content
|
|
|
chunks are (still) present in the repository (we check that via the chunks
|
|
|
cache).
|
|
|
@@ -714,7 +703,7 @@ different files, as a single path may not be unique across different
|
|
|
archives in different setups.
|
|
|
|
|
|
Not all filesystems have stable inode numbers. If that is the case, borg can
|
|
|
-be told to ignore the inode number in the check via --ignore-inode.
|
|
|
+be told to ignore the inode number in the check via --files-cache.
|
|
|
|
|
|
The age value is used for cache management. If a file is "seen" in a backup
|
|
|
run, its age is reset to 0, otherwise its age is incremented by one.
|
|
|
@@ -802,7 +791,7 @@ For small hash tables, we start with a growth factor of 2, which comes down to
|
|
|
|
|
|
E.g. backing up a total count of 1 Mi (IEC binary prefix i.e. 2^20) files with a total size of 1TiB.
|
|
|
|
|
|
-a) with ``create --chunker-params buzhash,10,23,16,4095`` (custom, like borg < 1.0 or attic):
|
|
|
+a) with ``create --chunker-params buzhash,10,23,16,4095`` (custom, like borg < 1.0):
|
|
|
|
|
|
mem_usage = 2.8GiB
|
|
|
|
|
|
@@ -887,7 +876,8 @@ Encryption
|
|
|
AEAD modes
|
|
|
~~~~~~~~~~
|
|
|
|
|
|
-Uses modern AEAD ciphers: AES-OCB or CHACHA20-POLY1305.
|
|
|
+For new repositories, borg only uses modern AEAD ciphers: AES-OCB or CHACHA20-POLY1305.
|
|
|
+
|
|
|
For each borg invocation, a new sessionkey is derived from the borg key material
|
|
|
and the 48bit IV starts from 0 again (both ciphers internally add a 32bit counter
|
|
|
to our IV, so we'll just count up by 1 per chunk).
|
|
|
@@ -909,24 +899,11 @@ even higher limit.
|
|
|
Legacy modes
|
|
|
~~~~~~~~~~~~
|
|
|
|
|
|
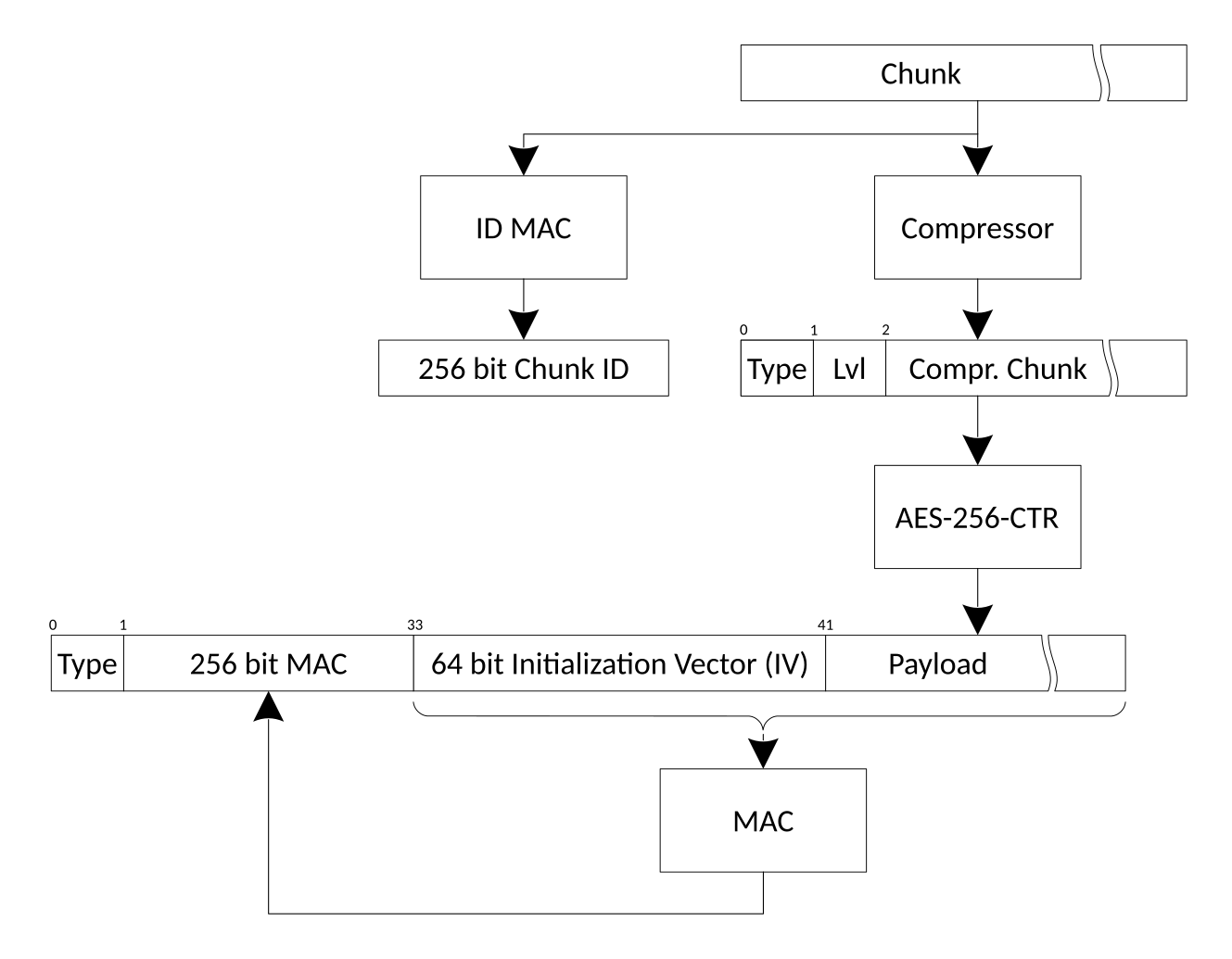
-AES_-256 is used in CTR mode (so no need for padding). A 64 bit initialization
|
|
|
-vector is used, a MAC is computed on the encrypted chunk
|
|
|
-and both are stored in the chunk. Encryption and MAC use two different keys.
|
|
|
-Each chunk consists of ``TYPE(1)`` + ``MAC(32)`` + ``NONCE(8)`` + ``CIPHERTEXT``:
|
|
|
+Old repositories (which used AES-CTR mode) are supported read-only to be able to
|
|
|
+``borg transfer`` their archives to new repositories (which use AEAD modes).
|
|
|
|
|
|
-.. figure:: encryption.png
|
|
|
- :figwidth: 100%
|
|
|
- :width: 100%
|
|
|
-
|
|
|
-In AES-CTR mode you can think of the IV as the start value for the counter.
|
|
|
-The counter itself is incremented by one after each 16 byte block.
|
|
|
-The IV/counter is not required to be random but it must NEVER be reused.
|
|
|
-So to accomplish this Borg initializes the encryption counter to be
|
|
|
-higher than any previously used counter value before encrypting new data.
|
|
|
-
|
|
|
-To reduce payload size, only 8 bytes of the 16 bytes nonce is saved in the
|
|
|
-payload, the first 8 bytes are always zeros. This does not affect security but
|
|
|
-limits the maximum repository capacity to only 295 exabytes (2**64 * 16 bytes).
|
|
|
+AES-CTR mode is not supported for new repositories and the related code will be
|
|
|
+removed in a future release.
|
|
|
|
|
|
Both modes
|
|
|
~~~~~~~~~~
|
|
|
@@ -947,13 +924,11 @@ Key files
|
|
|
|
|
|
.. seealso:: The :ref:`key_encryption` section for an in-depth review of the key encryption.
|
|
|
|
|
|
-When initialized with the ``init -e keyfile`` command, Borg
|
|
|
-needs an associated file in ``$HOME/.config/borg/keys`` to read and write
|
|
|
-the repository. The format is based on msgpack_, base64 encoding and
|
|
|
-PBKDF2_ SHA256 hashing, which is then encoded again in a msgpack_.
|
|
|
+When initializing a repository with one of the "keyfile" encryption modes,
|
|
|
+Borg creates an associated key file in ``$HOME/.config/borg/keys``.
|
|
|
|
|
|
-The same data structure is also used in the "repokey" modes, which store
|
|
|
-it in the repository in the configuration file.
|
|
|
+The same key is also used in the "repokey" modes, which store it in the repository
|
|
|
+in the configuration file.
|
|
|
|
|
|
The internal data structure is as follows:
|
|
|
|
|
|
@@ -963,24 +938,20 @@ version
|
|
|
repository_id
|
|
|
the ``id`` field in the ``config`` ``INI`` file of the repository.
|
|
|
|
|
|
-enc_key
|
|
|
- the key used to encrypt data with AES (256 bits)
|
|
|
-
|
|
|
-enc_hmac_key
|
|
|
- the key used to HMAC the encrypted data (256 bits)
|
|
|
+crypt_key
|
|
|
+ the initial key material used for the AEAD crypto (512 bits)
|
|
|
|
|
|
id_key
|
|
|
- the key used to HMAC the plaintext chunk data to compute the chunk's id
|
|
|
+ the key used to MAC the plaintext chunk data to compute the chunk's id
|
|
|
|
|
|
chunk_seed
|
|
|
the seed for the buzhash chunking table (signed 32 bit integer)
|
|
|
|
|
|
These fields are packed using msgpack_. The utf-8 encoded passphrase
|
|
|
-is processed with PBKDF2_ (SHA256_, 100000 iterations, random 256 bit salt)
|
|
|
-to derive a 256 bit key encryption key (KEK).
|
|
|
+is processed with argon2_ to derive a 256 bit key encryption key (KEK).
|
|
|
|
|
|
-A `HMAC-SHA256`_ checksum of the packed fields is generated with the KEK,
|
|
|
-then the KEK is also used to encrypt the same packed fields using AES-CTR.
|
|
|
+Then the KEK is used to encrypt and authenticate the packed data using
|
|
|
+the chacha20-poly1305 AEAD cipher.
|
|
|
|
|
|
The result is stored in a another msgpack_ formatted as follows:
|
|
|
|
|
|
@@ -990,15 +961,12 @@ version
|
|
|
salt
|
|
|
random 256 bits salt used to process the passphrase
|
|
|
|
|
|
-iterations
|
|
|
- number of iterations used to process the passphrase (currently 100000)
|
|
|
+argon2_*
|
|
|
+ some parameters for the argon2 kdf
|
|
|
|
|
|
algorithm
|
|
|
- the hashing algorithm used to process the passphrase and do the HMAC
|
|
|
- checksum (currently the string ``sha256``)
|
|
|
-
|
|
|
-hash
|
|
|
- HMAC-SHA256 of the *plaintext* of the packed fields.
|
|
|
+ the algorithms used to process the passphrase
|
|
|
+ (currently the string ``argon2 chacha20-poly1305``)
|
|
|
|
|
|
data
|
|
|
The encrypted, packed fields.
|

{kind=link}
{kind=link}